1.论文概要
研究背景:
论文链接。语义图像分割(Semantic image segmentation)一直是CV领域的热点。经过语义分割后,图像中的每个像素被分配一个类别标签。目前语义图像分割常用框架通常为把全连接替换为卷积层的全卷积网络。残差块的引入通过跳跃连接的引入有效的解决了梯度消失的问题。本文通过改进残差网络设计用于语义图像分割。
对于图像语义分割,“上下文信息”获取的越多越好。为了获取更多“上下文信息”现有的方法大多存在网络架构过于复杂,大规模的超参数调整的问题。本文提出的金字塔残差块简单而有效。不仅限于文中的任务,是一种可应用于基于ResNet的其他体系结构或任务的通用方法。
算法改进:
本文提出名为金字塔残差快(pyramid residual block),可以更好的利用上下文信息并增强关键特征。相比传统残差块,Pyramid残差块添加了两部分,首先是聚合基于不同区域上下文信息的Pyramid池化块,然后添加了注意力机制,能通过逐元素乘法运算自适应地重新校准特征响应,从而增强有用特征并抑制次要特征。
实验验证:
本文提出的金字塔残差块在PASCAL VOC 2012分段数据集中表现出色,并且在标准残差块上大大提高了分割精度。
2.算法应用
创新点1:Pyramid Pooling Module
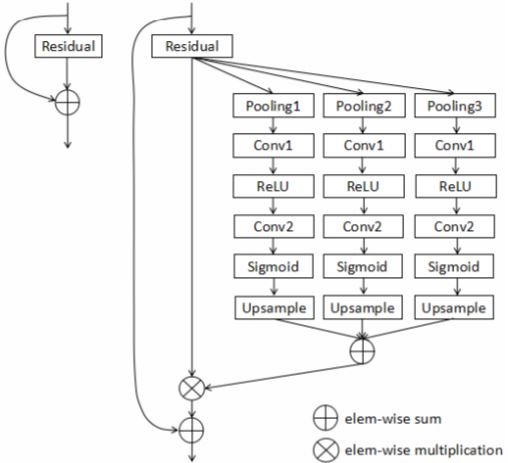
在图像语义分割中,已经有许多方法更有效地收集背景信息。[1]最先提出金字塔Pooling模块。[1]中金字塔汇集模块附在ResNet的顶部,而本文的金字塔汇集模块嵌入到ResNet的残差块中如图1。具体而言,细粒度或局部信息有助于实现良好的像素级精度,图像的全局背景能够澄清局部模糊性。在深度神经网络中,虽然理论上来自更高层次的特征已经具有超出输入图像尺寸的非常大的感受野,但实际上感受野的尺寸远小于理论尺寸。这阻碍了充分合并重要的上下文信息,Pyramid Pooling Module有效的解决了这个问题。
如图[1]所示,改进后的模块将来自残差块主分支的特征映射作为输入。它具有三个并行分支,每个分支包含一个池化层,一个ReLU激活函数,两个卷积层(1×1卷积),一个sigmoid函数和一个上采样操作。三个分支中的池的bin大小分别设置为1×1,2×2和4×4且都为平均池化。池化操作后的第一个卷积层用于降维。之后的第二卷积层用于维度增加,恢复原始信道数。再经过上采样操作后,来自三个并行分支的特征映射通过逐元素求和融合,得到注意力概率分布图(attention probability maps)。
创新点2:注意力机制
在金字塔池模块的每个分支中,对于第二个卷积后的激活函数,选择sigmoid函数而不是ReLU函数来规范化特征映射的每个元素。最终拿输出的注意力概率分布图和来自残差块主分支的特征图执行逐元素乘法运算。通过这种简单的方式,可以为更有用的特征响应分配更大的权重,从而有助于提高特征可辨性。
3.实验
实验数据集为PASCAL VOC 2012,广泛用于的语义分割数据集。包含20个对象类别和一个背景类。我们使用[2]提供的额外注释来增加数据,分别生成10582,1449和1456个用于训练,验证和测试的图像。
使用随机梯度下降(SGD)训练模型,批量大小为10,最大迭代次数为20K。为了增强数据,对所有训练图像使用随机镜像和随机裁剪。使用已经在ImageNet数据集上预训练的ResNet-50或ResNet-101网络作为基础模型。最后一个残余块的输出由1×1卷积层和softmax非线性处理,以产生最终的像素分割结果。
为了探索降维对性能的影响,用金字塔残差块替换ResNet-50的最后残差块(res5c),并将维数降低层的通道数(即图1中的’Conv1’)设置为分别为1024,512,256和128。结果显示合理压缩特征的维数可以在一定程度上提高分割精度;这可能是因为删除了冗余特征。但是,当维数降低太多时,由于判别特征的丢失,结果又会变差。本实验显示当通道数为256时效果最好。
为了评估单个组件的有效性,分别保留金字塔池模块和注意力机制两个组件中的一个并移除另一个。实验结果显示每个组件都有利于分割效果,当二者合并时效果最好。
由于具有一个金字塔残差块(res5c)的ResNet-50在很大程度上优于基本模型,实验进一步用金字塔残差块替换原始ResNet-50的两个块(res5c和res4f)和三个块(res5c,res4f和res4c)。实验结果显示,具有两个金字塔残差块的模型比仅有一个金字塔残差块的模型带来了0.91%的改进,具有三个金字塔残余块的模型进一步将性能提高了0.71%。因此,本文提出的金字塔残差块对于改进基于ResNet的语义分割系统是简单而有效的。
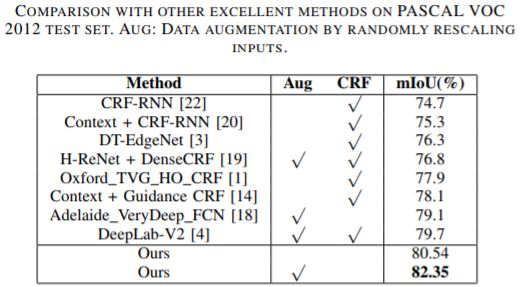
为了探究更深层次的神经网络是否有利于像素方式的语义分割。实验采用预先培训的ResNet-101,其修改与ResNet-50相同。以相同的方式,一个块(res5c),两个块(res5c和res4b22)和三个块(res5c,res4b22和res4b19)分别被金字塔残余块替换。实验结果显示,相同的设置下,ResNet-101在很大程度上优于ResNet-50。此外,当更换的块数增加时,性能从71.27%提高到75.38%。更深层次的ResNet也受益于更多金字塔剩余块。对比实验结果如图2。
☛参考文献
[1] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” arXiv preprint arXiv:1612.01105, 2016
[2] B. Hariharan, P. Arbelaez, L. Bourdev, S. Maji, and J. Malik, “Semantic ´contours from inverse detectors,” in Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011, pp. 991–998.

